Local LLMs can now handle ticker mapping for alternative data
Benchmarking open-weight LLMs for ticker mapping
 ·
·
Inference cost, data custody requirements, and privacy concerns need not limit the accuracy of text labeling and featurization in alternative data (alt data) pipelines. We find that an ensemble of four open-weight LLMs matches the leading light closed-weight models on ticker mapping quality. Such ensembles of open-weight models approach the flagship closed-weight models’ effectiveness. And it doesn’t even require an ensemble: DeepSeek V4 Flash, small enough for workstation-class self-hosting, comes within 0.002 F1 of its flagship sibling on its own.
This article benchmarks eight open-weight models (four flagship models and four light variants, some with <100 billion parameters, from DeepSeek, Qwen, Mistral, and Llama) against the canonical reference dataset from our ticker mapping benchmark. The best individual open-weight models track the closed-weight light tier. Ensembling models closes the gap to closed-weight flagship models.
These results focus on output quality, the part our benchmark is built to measure. Turning a capable model into a reliable, point-in-time production pipeline is the harder problem, and one we touch upon at the end. For data sellers and funds, the rapid improvement of open-weight models enables the ability to build text-derived features inside a controlled, auditable, point-in-time pipeline.
Background
Part 1 of this series benchmarked closed-weight models from OpenAI, Anthropic, Google, and xAI on a ticker mapping task: extract every US-listed equity ticker for companies mentioned in a body of financial text. For example, given an article that mentions “Apple,” “Meta,” and “GM,” the task is to return AAPL, META, and GM while avoiding false matches, stale tickers, subsidiaries, product names, and ambiguous company references. Multi-model consensus produced reliable canonical labels, and majority voting across cheaper light (fast, express) models beat most flagship (frontier) models. This article uses the same methodology and benchmark as part 1. The overall measure we use, F1, is the harmonic mean of precision (the share of returned tickers that are correct) and recall (the share of the correct tickers the model found). F1 runs from 0 to 1, and rewards a model that both avoids both false tickers and missed ones.
Regulated teams with data sovereignty and related regulatory constraints often cannot send their data outside of the enterprise; for them, self-hosted open-weight models may offer the only path. Cost concerns, especially for pipelines with large throughput, may also favor open-weight and self-hosted models. All eight models we test are open-weight and can run on your own hardware. The light variants can run on workstation-class hardware; the flagships need a multi-GPU server. We analyze whether these approaches can support a given quality requirement.
Flagship open-weight models
We sent each article to four flagship open-weight models: DeepSeek V4 Pro, Llama 4 Maverick, Mistral Large 2512, and Qwen 3.6 Plus. At the time of writing, these were the latest flagship model releases from each vendor and the candidates to pick when quality matters more than cost. Based on the past pattern of eventual releases, we classify Qwen 3.6 Plus as an open-weight model, but its release roadmap remains unclear and this could be considered a closed-weight frontier model.
Flagship open-weight performance against the canonical stock ticker labels is as follows:
| Model | Precision | Recall | F1 |
|---|---|---|---|
| Qwen 3.6 Plus | 0.889 | 0.923 | 0.906 |
| DeepSeek V4 Pro | 0.862 | 0.948 | 0.903 |
| Mistral Large 2512 | 0.887 | 0.847 | 0.867 |
| Llama 4 Maverick | 0.858 | 0.753 | 0.802 |

Qwen 3.6 Plus and DeepSeek V4 Pro lead at 0.906 and 0.903 F1, essentially tied. Qwen balances precision and recall; DeepSeek pushes recall to 0.948, the highest of any open-weight model, and drops precision to 0.862, producing more false-positive ticker labels. Mistral Large sits at 0.867. Llama 4 Maverick scores 0.802 with a recall of 0.753, missing about one in four canonical mentions.
Light open-weight models
We next examined four open-weight models, some with <100 billion parameters, suitable for workstation-class self-hosting: DeepSeek V4 Flash, Llama 4 Scout, Mistral Small 2603, and Qwen 3.6 35B-A3B (a mixture-of-experts model with 35B parameters and roughly 3B active per token).
Below are the results for light open-weight models against the same canonical labels:
| Model | Precision | Recall | F1 |
|---|---|---|---|
| DeepSeek V4 Flash | 0.871 | 0.933 | 0.901 |
| Qwen 3.6 35B-A3B | 0.846 | 0.900 | 0.872 |
| Mistral Small 2603 | 0.799 | 0.800 | 0.799 |
| Llama 4 Scout | 0.863 | 0.735 | 0.794 |

DeepSeek V4 Flash is the headline. At 0.901 F1 it matches its flagship sibling (0.903) — a negligible 0.002 step-down in performance unmatched in either tier, open or closed. Qwen 35B-A3B, which is well-suited for local deployment, holds the second place at .872. Mistral Small and Llama 4 Scout perform substantially worse.
The full picture: ranking 16 models
Combining the closed-weight results from our earlier research with the open-weight numbers above gives the following ranking of all sixteen models tested:

Qwen 3.6 Plus (0.906) and DeepSeek V4 Pro (0.903) are comparable to Grok 4.1 Fast, and outperform most closed-weight light models. DeepSeek V4 Flash, which is also small enough for workstation-class self-hosting, ties GPT-5.3 Chat at 0.901 and beats Gemini Flash Lite, Claude Haiku 4.5, and Grok 4.20 Beta. Only the three top closed-weight flagship models (Claude Opus, Gemini Pro, and GPT-5.4) clearly beat the open-weight leaders, and the gap shrinks once we ensemble the light models as discussed below.
What going light costs you
Performance degradation varies by provider:

DeepSeek’s performance drop is the smallest: F1 falls 0.002, and precision actually rises. An alt data pipeline using DeepSeek would face the lowest cost-to-quality tradeoff in this benchmark.
Ensembling the open-weight models
We applied the same two-of-four agreement rule from Part 1: each article runs through all four models independently, and a ticker is retained when at least two models agree.
Ensemble performance at ≥2/4 majority vote:
| Ensemble | Precision | Recall | F1 |
|---|---|---|---|
| Closed-weight flagship ≥2/4 | 0.988 | 1.000 | 0.994 |
| Open-weight flagship ≥2/4 | 0.886 | 0.952 | 0.917 |
| Closed-weight light ≥2/4 | 0.893 | 0.942 | 0.917 |
| Open-weight light ≥2/4 | 0.859 | 0.898 | 0.879 |

The open-weight flagship ensemble achieves 0.917 F1, matching the closed-weight light ensemble from Part 1 and within 0.077 F1 of the closed-weight flagship ensemble (0.994). Voting works here for the same reason it worked in Part 1: vendor error patterns are largely uncorrelated, so a false positive in one model rarely repeats in another, and the complementary biases we documented in closed-weight models reappear in open-weight form.
Set against individual closed-weight models, the open-weight flagship ensemble (0.917 F1) sits between the three top closed-weight flagships and the rest of the field, beating five of the eight individual closed-weight models tested in Part 1. The open-weight light ensemble (0.879 F1) is competitive: it ties Gemini Flash Lite, beats Claude Haiku 4.5 and Grok 4.20 Beta, and trails the light closed-weight models by less than three F1 points.
Open-weight ensembles versus individual closed-weight models, ranked by F1:
| Model / Ensemble | Type | F1 |
|---|---|---|
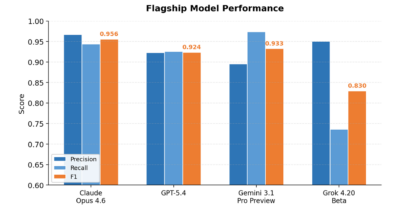
| Claude Opus 4.6 | Closed-weight flagship | 0.956 |
| Gemini 3.1 Pro Preview | Closed-weight flagship | 0.933 |
| GPT-5.4 | Closed-weight flagship | 0.924 |
| Open-weight flagship ensemble | Open-weight flagship | 0.917 |
| Grok 4.1 Fast | Closed-weight light | 0.908 |
| GPT-5.3 Chat | Closed-weight light | 0.901 |
| Gemini Flash Lite | Closed-weight light | 0.879 |
| Open-weight light ensemble | Open-weight light | 0.879 |
| Claude Haiku 4.5 | Closed-weight light | 0.853 |
| Grok 4.20 Beta | Closed-weight flagship | 0.830 |

When to self-host
Picking a model is relatively easy; running it well on a continuous basis is more difficult. The cost-and-latency tradeoffs change once the model runs on your hardware. Self-hosted inference on a stack like Ollama and vLLM is a fixed hardware outlay against predictable throughput and electricity costs. For high-throughput pipelines that process hundreds or even thousands of documents per day, the payback may arrive in months. We will consider such economic details in future research.
Self-hosting also removes a class of compliance blockers. Regulated information and licensed primary sources cannot leave the perimeter in some enterprises; open-weight models run locally meet that bar. The approach is also a powerful antidote to the otherwise intractable problems of LLM look-ahead bias, enabling point-in-time (PiT) evaluation on models with defined provenance. Self-hosting makes it easier to pin model provenance and build fpoint-in-time workflows.
From benchmark to pipeline
A benchmark like this helps address whether open-weight models can be used for ticker mapping: which ones are accurate enough, and where ensembling can make a difference. Putting these models into production pipelines raises some additional challenges worth planning for.
Pipelines need to smoothly deal with failure and with edge cases, as tickers get reused and remapped, or entity mapping ambiguity sneaks in. Quality monitoring and assurance testing also have to become part of the workflow. From the perspective of funds consuming the model outputs, it is also tremendously helpful if the outputs are point-in-time. Funds know that non-PIT mapping creates significant problems with lookahead and survivorship, so rigorous, auditable versioning is of major benefit.
These pieces are easiest to get right if you plan from the start.
Conclusions
Open-weight models are suitable for ticker mapping in alternative data pipelines. Qwen 3.6 Plus and DeepSeek V4 Pro beat every closed-weight light model except Grok 4.1 Fast, and trail the best closed-weight flagship by five F1 points. Ensembling closes that gap. And the bar can be cleared on local hardware alone: DeepSeek V4 Flash scores 0.901 F1 with workstation-class self-hosting — all but matching the open-weight flagships — a strong option for teams that prefer to keep their data fully in-house. The choice among standard cloud and self-hosted models is a financial, operational, and compliance question.
Inference cost and regulatory constraints no longer set the ceiling on what alternative data products you can build from text because, for this ticker-mapping benchmark, model quality is no longer the only binding constraint. The limits are now design, industry expertise, and operational excellence. Teams that can access the required capabilities unlock the option value of stranded predictive datasets.
The gap between a model that can map tickers and a pipeline that produces reliable systematic data products is what we work on at vBase. If you’re building these pipelines for your own data, we’re happy to compare notes.
Related research from vBase
- How good are LLMs at tickerization?
- Your LLM’s alpha might be mere memorization
- If data is the new oil, LLMs are the shale revolution
Shunran is a recent graduate of Cornell University’s Master of Financial Engineering program. Her work focuses on quantitative research and systematic investing, using alternative data and machine learning to generate tradable signals. At vBase, she developed portfolio strategies using sentiment data, and built LLM-based tickerization pipelines.