Sell Alternative Data Faster
Package your data so funds trust, trial, and buy.

Much valuable data remains unsold or undersold
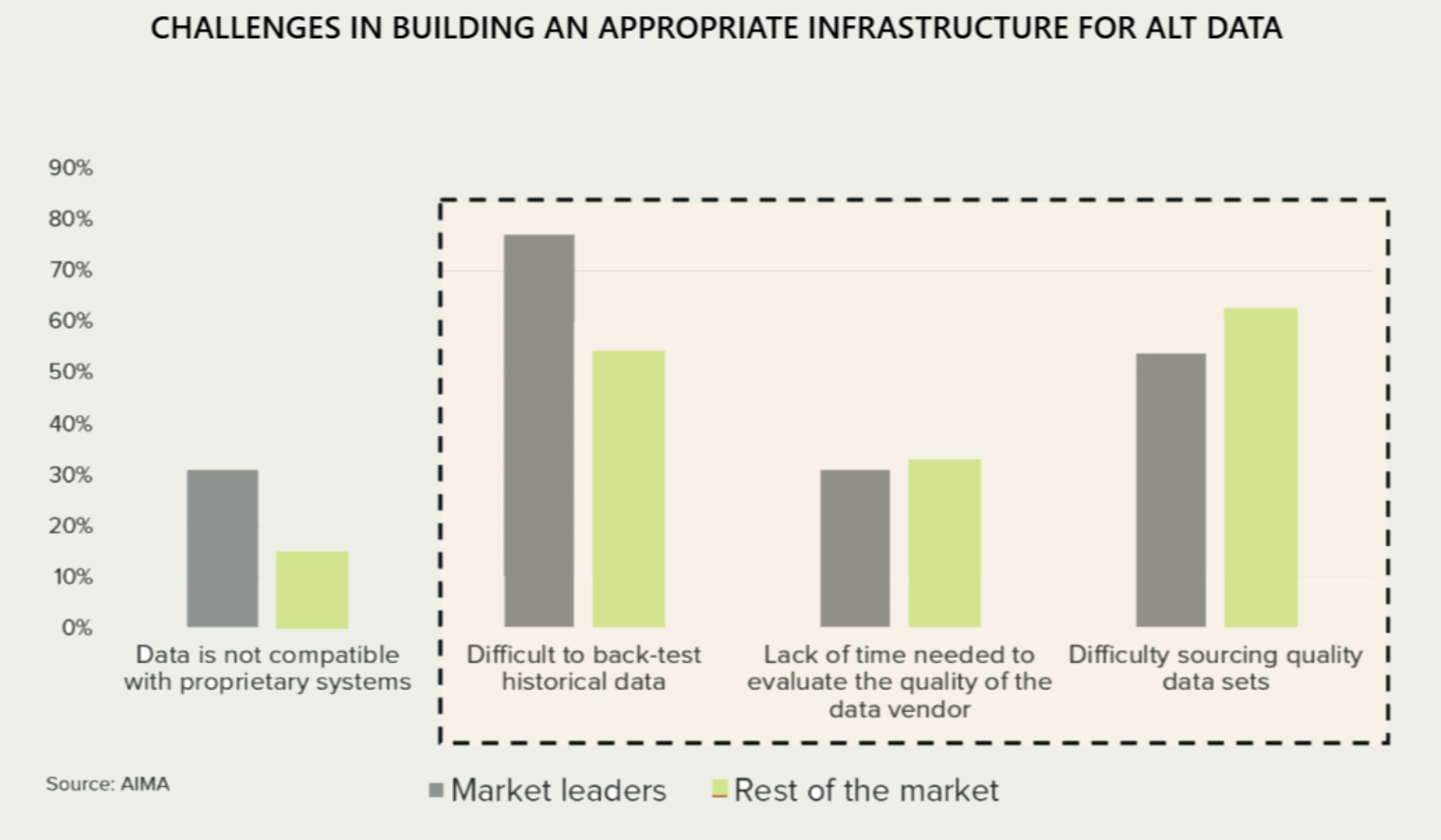

Real-world data rarely arrives ready to sell.
Featurized
Raw data is just noise until it's transformed into structured quantitative signals. Funds want clean, analysis-ready features they can plug directly into their models — not datasets that require weeks of engineering before anyone can run a single backtest.
Tickerized
Investment teams think in tickers, not company names or URLs. Mapping your data to standard identifiers (tickers, FIGIs) is table stakes — without it, systematic investors can't reliably backtest or merge your dataset with anything else in their pipeline.
Consistently delivered
A dataset that shows up late, changes schema, or goes dark for a week undermines production trading pipelines. Institutional buyers expect production-grade delivery: on schedule, in a stable format, with monitoring that catches issues before they do.
Provably point-in-time
Quants need to know exactly what was available on any given date — and to be sure that your history contains no retroactive revisions, overwrites, or look-ahead bias. If you can't quickly prove your data's history is point-in-time and complete, many systematic investors won't seriously evaluate it.
Why most alternative data trials fail
Fewer than 1 in 5 data vendor trials end in a purchase. Four failure modes account for most of the losses.
-
Too much work to backtest
When data isn't ready for a research pipeline, quant teams have to invest heavily before they even know if there's a signal. Winning providers ship evaluation-ready data with meaningful numerical features mapped to standard tickers. Time-to-first-backtest is the single biggest predictor of trial success.
-
Unverifiable history
Backtesting against revised or restated data produces false signals. Funds have been burned enough times that "trust us, it's point-in-time" doesn't cut it. Winning providers offer verifiable proof that history is complete and point-in-time, so funds can backtest with conviction.
-
No reference backtests
Providers who ship raw data are missing a commercial opportunity. Reference backtests showing key use cases do double duty: they provide evidence the data is worth evaluating, and show that it can be deployed into a research pipeline without significant engineering. Without them, many buyers won't invest the effort.
-
Unreliable delivery
Buyers see consistent professional delivery as evidence of operational maturity. Winning providers deliver versioned historical data via standard cloud storage (not locked behind a proprietary API), a live feed on a reliable schedule, clear delivery specifications, and advance notice of schema changes.
Trust is the new alpha
vBase makes data trial-ready, verifiably live, and provably point-in-time
1 line of code unlocks years of investor trust
Maximize your data's value
vBase team brings decades of experience in building:
- Ticker mapping -- let buyers get started without expensive data prep
- Quant-ready features -- built for how funds research
- Point-in-time audit trails -- enable funds to build conviction faster
- Backtesting -- let buyers see your edge
- Live pipelines -- produce and deliver at institutional grade

Give buyers immediate, shareable proof of value
We build and maintain live indices from your data, so buyers can see your data's real track record
- Showcase alpha with a live, out-of-sample track record
- No more rebuilding decks for every prospect, share a single link that stays current
- Fully reproducible, enabling buyers to validate and reproduce your results


Frequently Asked Questions
Alternative data is information investors use beyond traditional financial statements, market data, company filings, and broker research. Examples include consumer transaction data, web data, app usage, social media, geolocation, expert-call transcripts, reviews, supply-chain data, and other operational datasets that may contain predictive investment signals.
The strongest datasets are timely, with at least a couple years of history, and are connected to the performance of tradable securities. For systematic investors, the data also needs to be packages so that it can be evaluated and adopted quickly, meaning it should have a clean consistent schema, mapped to securities, featurized, and delivered in a reliable format to standard storage.
Quant-ready data is structured for research and production use. That usually means numerical features, ticker or FIGI mapping, stable schemas, historical coverage, clear documentation, point-in-time history, and delivery through a format that a fund can plug into its research pipeline.
Point-in-time data shows what was actually known or delivered at a given moment in the past. This matters because backtests built on revised, backfilled, or overwritten history often introduce bias into the quant research pipeline.
Systematic investors need to know whether a strategy could actually have been traded using the data available at the time. If historical files include revisions, survivorship effects, future mappings, or overwritten values, a backtest will make a strategy’s historical performance unrepresentative of its live performance. This results in extremely costly mistakes for quants.
It’s not a hard requirement, but it’s often very helpful. A reference backtest does not replace the buyer’s own research, but it shows the data can be transformed into a usable signal, helps buyers understand potential use cases, and reduces the internal effort required to justify a trial.
No. Point-in-time validation proves the integrity and timing of the historical record. It allows hedge funds to evaluate the data and judge whether it contains “alpha” within their research process. If data is not verifiably point-in-time, then any alpha the historical data shows will be treated with skepticism. If data is verifiably point-in-time, systematic investors can trust the results of their own historical analysis.
vBase helps data providers make their datasets easier for systematic investors to evaluate. Our tools provide proof that historical data is point-in-time. In additional we help data providers fill gaps in their packaging for systematic investors, including ticker mapping, feature engineering, live reference backtests with shareable dashboards, and institutional-grade data delivery.
Yes. Many valuable datasets start as messy operational data, text, audio, transcripts, social content, web data, or other unstructured sources. vBase helps transform raw data into structured, investment-relevant features that can be tested and delivered to institutional buyers.
The best place to start is a conversation to understand where you are and where your product may have relevant gaps. Our trial readiness checklist, gives you a self-inventory you can perform as well.