If data is oil, AI is the shale revolution
How to recognize stranded data assets — and what to do with them.
 ·
·

On December 10, 1967, the U.S. government detonated a 29 kiloton nuclear device under a rock formation near Dulce, New Mexico in an attempt to unlock shale gas.
With hindsight, this approach to natural gas development sounds cartoonishly extreme, and that’s the point. People knew the shale gas was there and its economic value was clear. But it took the shale revolution of the early 2000s to achieve what nuclear bombs could not, converting shale gas from tantalizingly out of reach to economically recoverable.
Before LLMs, much of the world’s unstructured data looked like shale deposits in the 1960s: obviously valuable, widely available, and too expensive to develop. In the case of data, internal databases, rich text archives, logs, video, and other messy sources have long held enormous potential, but often remain economically stranded.
LLMs have changed the economics. They make it feasible to run extraction passes through unstructured raw material, converting it into structured time series ready for use by systematic investors and other buyers at far lower cost than before.
While AI doesn’t make every dataset valuable, it has expanded the set of datasets that are now economically worth developing. This shift in economics means organizations sitting on previously impossible-to-develop data acreage may now be sitting on a valuable asset.

If your organization runs on unstructured text — support, sales, research, compliance, or operational data — the economics that once made it too expensive to productize may no longer apply.
My perspective on this shift comes from both sides of the table, having previously run a systematic fund that evaluated external datasets and now working with data owners.
What AI has changed
Until recently, unlocking the signal in unstructured data was brutally expensive. Classifying 10,000 earnings call transcripts by company mentions, sentiment, and events the old way was roughly a 7,500-hour project. This is on the order of $150,000–$500,000 in skilled-analyst time, depending on whether you used in-house talent or a blended onshore/offshore team. If you were sure the data was worth it, you could build a business around the manual pipeline. Most data owners weren’t, and didn’t.
Before LLMs, much of the world’s unstructured data looked like shale deposits in the 1960s: obviously valuable, widely available, and too expensive to develop.
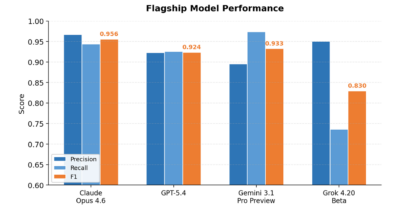
LLMs have cut this cost by 5-20x when outputs are human-verified, and up to ~100x when small-sample auditing is acceptable. Similar gains apply to entity tagging, identifier resolution, and topic classification. For many data owners, the falling cost of converting messy text into investor-usable features is low enough that the question shifts from can we develop this data to should we.

Rich text sources like transcripts and research notes are the obvious beneficiaries. Think of a boutique research firm whose 15 years of analyst reports trace thesis shifts across a sector; a conference organizer with a decade of panel transcripts from industry executives; or a trade publisher whose archives hold years of sector-specific reporting and company profiles.
But semi-structured exhaust from ordinary operations like support tickets, CRM notes, procurement logs, purchase orders, and compliance records is also now in scope. Data that used to be too expensive to normalize at scale is now within reach.
Not sure whether this describes you? If your data is hard for others to reproduce and can be aggregated to say something measurable about publicly traded companies or assets, please read on.
The most direct path to commercial value is usually simple, interpretable, quantitative features like topic intensity, sentiment trends, asset-level indicators, that buyers can evaluate systematically. Systematic use cases are often the best entry point into the data market because systematic investors have active demand for novel data, standard packaging requirements, and rigorous evaluation. This forces a clean, well-documented dataset that can be repackaged for other buyers later.
Your strategic options (and why not every business needs to become a data company)
For most companies, most stranded data should stay stranded. Monetization is often a multi-year commitment that competes with your core business for executive attention, specialist hires, and capital.
However, some data acreage truly has become West Texas shale. For those, the question is how to realize that value. And just as every landowner in West Texas didn’t become an oil & gas exploration firm, not every data owner needs to become an alt-data vendor. In the shale boom, most landowners worked with specialist firms who developed the acreage on their behalf. Similar patterns are now emerging in data.
There are a few viable paths, with varying levels of effort, risk, and reward.
For most companies, most stranded data should stay stranded.
Option A: Sell the acreage
This is the simplest route. License access or usage rights to your assets and let someone else develop them. This makes sense when you do not want to build a product organization yourself and the data is compelling enough to attract a buyer who does.
The tradeoff is that raw data, like undeveloped reserves, tends to trade at a discount. A buyer needs to account for the cost of development and the risk that the finished product doesn’t sell.
The most natural buyer is often an existing data provider looking to source new data (for example a web traffic firm acquiring a clickstream dataset), or a specialized data development company.
Option B: Partner with a specialist
If you want more upside than a straight license, partner with a specialist. You provide the raw material and the domain knowledge, they bring engineering, productization, and often distribution. You share economics, but you reach revenue faster without taking on a product team.
For many organizations, this is the middle path: meaningful upside without becoming a full-time data product business. validityBase is one example of a firm that works with data owners in this way.
Option C: Develop the field yourself
This is the highest payoff and the highest commitment. You own the full stack: extraction, packaging, documentation, delivery, support, and sales. You build and maintain the pipeline, develop the customer relationships, and capture the full economics.
This path requires specialized expertise beyond data engineering. You need to identify and distill the predictive elements of your data in a way that integrates with systematic investment workflows. It’s a real product business, but for organizations with the right data and the willingness to invest, it’s also where the most value accrues.
Three paths to realize the value of your data
Matched to your appetite for effort, time-to-market, and upside.
| OPTION ASell the acreage | OPTION BPartner with a specialist | OPTION CDevelop the field yourself | |
|---|---|---|---|
| What you provide | Data access / usage rights | Data + domain knowledge | Data + full product team |
| Effort | Low | Moderate | High |
| Your share of economics | Discounted (raw data) | Shared | Full capture |
| Key risk | Lower realized value | Partner execution & fit | Product-market fit risk |
| Best for | Owners with no appetite to build a product org | Want upside without becoming a full-time data business | Right data and willingness to invest in a product business |
validityBase, 2026.
Even if you ultimately plan to sell or partner on your data assets, you can increase their value materially by derisking the next step in the process. Most alternative data trials fail — roughly 80% by some estimates. That makes relatively modest upstream work unusually valuable — basic structuring, entity mapping, and documentation can significantly improve the appeal of your data for buyers and partners. It reduces their work and signals that you are willing to stand behind the dataset.
Sitting on stranded data?
Book a 30-minute working session with us — we’ll look at what data you have, tell you what’s worth developing, and share how comparable data gets priced. Or email me at dan@vbase.com.
Already planning to develop your data? Our trial readiness checklist walks through the prep systematic buyers expect.
Before vBase, Dan founded Clerkenwell Asset Management, a systematic hedge fund that bought and evaluated external data to build trading strategies. He brought that buyer-side perspective to vBase, which builds infrastructure for teams making credible predictive claims.